After several months working part-time on optimizing McFACTS, I think we're rapidly approaching saturation: one by one, we've cut the tall poppies down, cooled the hot paths, until the largest contributors to the runtime are either bookkeeping functions which are already very simple as they are, or calculations that are genuinely time-consuming and which we've already optimized a good deal.
Well, that's not quite right. We've done this for the top-level function calls used directly from main(). But that just means we now have a ton of utility functions, scattered all over the codebase, which take way longer than they have any right to be. And as it happens, our worst offenders are related to AstroPy unit conversions.
Meet r_schwarzschild_of_m:
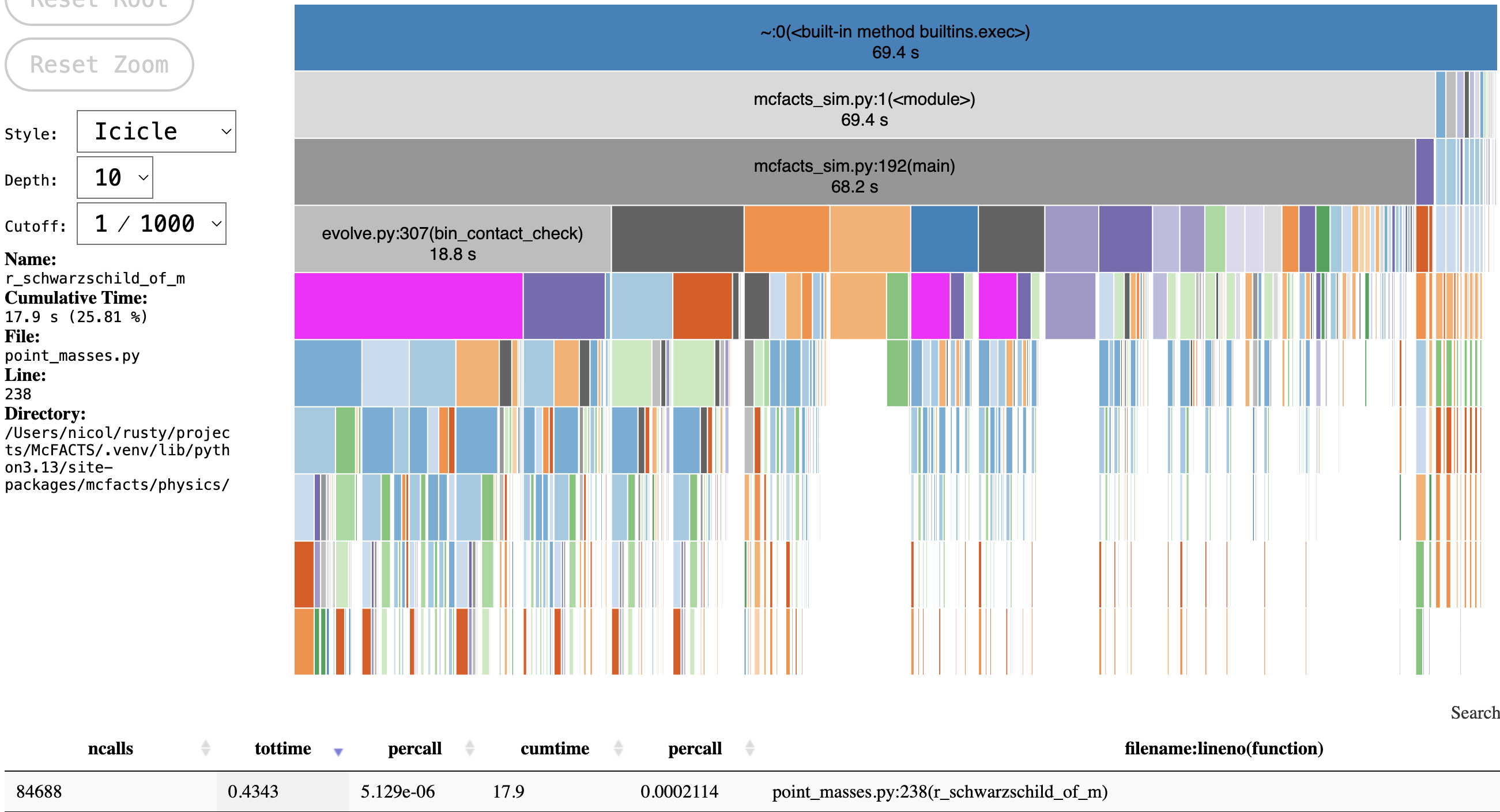
After many rounds of optimizations, this little troublemaker of a function profiled at ~25% of total simulation runtime. Now, this is via cProfile, which tends to exaggerate the impact of small, frequently-called functions, but the actual figure is still in the 15-20% range. What does it actually do?
def r_schwarzschild_of_m(mass): """Calculate the Schwarzschild radius from the mass of the object. Parameters ---------- mass : numpy.ndarray or float Mass [Msun] of the object(s) Returns ------- r_sch : numpy.ndarray Schwarzschild radius [m] with `astropy.units.quantity.Quantity` """ # Assign units to mass if hasattr(mass, 'unit'): mass = mass.to(u.solMass) else: mass = mass * u.solMass r_sch = (2. * const.G * mass / (const.c ** 2)).to(u.m) assert np.isfinite(r_sch).all(), \ "Finite check failure: r_sch" assert np.all(r_sch > 0).all(), \ "r_sch contains values <= 0" return (r_sch)
One input. One output. An attribute check, a few unit conversions and a couple integrity checks. An estimated 200μs per call on a Mac M3 Max. How the hell does that happen?
This function calculates the Schwarzschild radius of an object - the minimum size beyond which an object of a given mass must collapse into a black hole. For our purposes, we want to accept a mass denoted in solar masses solMass and then calculate the radius in SI meters.
But things are never quite that simple.
The mass argument could be a scalar or a 1-d array: it could be a unitless number, or it could be an AstroPy Quantity object wit an associated unit. And that unit could be any compatible mass type, from grams to jovian masses to kilograms to solar masses. We assume, in the unitless case, that the mass being passed in is denominated in solar masses, but if it possesses units, we need to check that, and coerce it into solar masses if it turns out to be another mass unit.
Once the mass is confirmed to be correctly denominated (or we don't have enough information and just assume the happy path), we can perform the actual calculation, taking advantage of AstroPy's built-in cosmic constants which handle unit conversions correctly, and then convert the final result to meters.
All very well and simple, right? But this is Python, which means that this decomposes into a tree of function calls up to 20 layers deep.
This gives us such darling call sequences as __mul__ > __array_unfunc__ > converters_and_unit > helper_twoarg_comparison > get_converters_and_unit > get_converter > get_converter (from core.py this time, not helpers.py) > _to > __repr__ > __format__ > to_string > to_string (from base.py rather than core.py) > _format_unit_list > <method 'join' of 'str' objects> > genexpr > _format_unit_power > _get_format_name > <method 'get' of 'dict' objects>.
That's dozens upon dozens of function calls, runtime checks, small memory allocations, just to create a single new object.
So you can probably understand why my reaction to this is to step away from Python, pull up maturin, and rewrite the exact, narrow operation I need in a lower level language: do exactly what we need, in the simplest way possible, and no more.
That turns out to not be all that much code, and the vast majority of it is just involved with safely wrangling Python types.
#[pyfunction] pub fn r_schwarzschild_of_m_helper<'py>(py: Python<'py>, mass: &Bound<'_, PyAny>) -> PyResult<FloatArray1<'py>> { // extract the attribute if it exists, and if so, make sure it's denominated in solar masses if let Ok(array_quantity) = extract_array_unit(mass) { // allocate the output array up front let out = unsafe {PyArray1::new(py, array_quantity.values.len().unwrap(), false)}; let out_slice = unsafe {out.as_slice_mut().unwrap()}; // coerce unit to solar masses so that we can later coerce to kg // yes, it's a bit silly, but that's what the original does too let coeff = match array_quantity.unit { Unit::Gram => { Ok(M_SUN_G) } Unit::Kilogram => { Ok(M_SUN_KG) }, Unit::EarthMass => { Ok(EARTH_TO_SOL) }, Unit::JupiterMass => { Ok(JUPITER_TO_SOL) }, Unit::SolarMass => { Ok(1.0) }, _ => Err( PyTypeError::new_err( format!("Unsupported unit for r_schwarzschild_of_m: {:?}", array_quantity.unit) ) ) }?; array_quantity.values.as_slice().unwrap().iter().enumerate().for_each(|(i, val)| { let solmass = val / coeff; let r_sch = (2.0 * G_SI * solmass / (C_SI.powi(2))) * M_SUN_KG; out_slice[i] = r_sch; }); Ok(out) // otherwise, assume it's a numpy float array } else if let Ok(masses) = mass.extract::<PyReadonlyArray1<f64>>() { // allocate the output array up front let out = unsafe {PyArray1::new(py, masses.len().unwrap(), false)}; let out_slice = unsafe {out.as_slice_mut().unwrap()}; // no unit, so just assume it's in solar masses already masses.as_slice().unwrap().iter().enumerate().for_each(|(i, val)| { let r_sch = (2.0 * G_SI * val / (C_SI.powi(2))) * M_SUN_KG; out_slice[i] = r_sch; }); Ok(out) // otherwise, we've received an invalid input type } else { panic!("Unsupported input type for r_schwarzschild_of_m: mass input must be an array") } } /// Helper function for turning an AstroPy Quantity into a local ArrayQuantity pub fn extract_array_unit<'py>(ob: &Bound<'py, PyAny>) -> PyResult<ArrayQuantity<'py>> { // extract numerical value let values = ob.getattr("value")?.extract::<PyReadonlyArray1<f64>>()?; // extract unit value let unit_obj = ob.getattr("unit")?; // use python method to extract string representation let binding = unit_obj.call_method0("to_string")?; let unit_str: &str = binding.extract()?; // if we get a match on a simple type, return directly if let Ok(unit) = parse_unit(unit_str) { Ok(ArrayQuantity { values, unit }) } else { panic!("Could not parse unit {unit_str}") } } pub fn parse_unit(unit_str: &str) -> PyResult<Unit> { // match directly on bytes rather than performing string comparisons: see previous blog post for details! match unit_str.as_bytes() { b"kg" | b"kilogram" => return Ok(Unit::Kilogram), b"t" | b"tonne" => return Ok(Unit::MetricTon), b"earthMass" | b"M_earth" => return Ok(Unit::EarthMass), b"jupiterMass" | b"M_jup" => return Ok(Unit::JupiterMass), b"solMass" | b"Msun" => return Ok(Unit::SolarMass), b"m" | b"meter" => return Ok(Unit::Meter), _ => Err( PyTypeError::new_err( format!("Failed to parse unit: {}", unit_str) ) ) } }
The only difference here is that, unlike the original, we only accept array inputs, not scalar inputs. As it turns out, nowhere in our current codebase do we actually pass in a scalar mass, only arrays. If we wanted to support scalar inputs as well, it would just mean another couple of cases with virtually identical bodies.
Is this the most optimized Rust code ever? Hell no. In the unit branch, we're coercing the unit to solar masses just so we can coerce it to kilograms later. I haven't even thought about interning strings to avoid further allocations (though it's not clear how much that would help here).
Is this the most flexible code? Also no: the unit parsing assumes everything is just a basic irreducible unit, as opposed to a compound unit, and even then it only supports a few possibilities.
As it stands, the code above replicates only a tiny fraction of AstroPy's functionality, with none of the rich features and flexibility that make it useful.
But the tiny fraction of functionality it does replicate is exactly what we need, and no more. The results? A 40-fold speedup between the original and new wrapper function (with the majority of runtime still being spent in the Python wrapper, rather than the Rust helper):
def r_schwarzschild_of_m_optimized(mass): if mass.shape == (0,): if hasattr(mass, 'unit'): return mass.to(u.m) else: return mass * u.m else: return r_schwarzschild_of_m_helper(mass) * u.m
Where the original took ~200μs/call, this wrapper takes 5μs/call, with only 1μs spent in the helper function where the actual work happens.
Even one microsecond might seem like too much time, given how little work is being done: most of that is spent in FFI. If the original code had been written in a high-level language with better performance characteristics like Go, or maybe even TypeScript, it's not inconceivable that the FFI cost here would complicate our choice to use a lower-level language for such a small operation. But here, the FFI cost is tiny compared to the runtime cost of the original function, which was just a few lines of Python... which were actually hiding dozens upon dozens of function calls which contribute dubiously to our ultimate goal.
(After I spent the last blog post fixated on whether string or byte matching would help shave a nanosecond off runtime, I feel a bit silly. Regardless of method, match time is utterly swamped by FFI costs. Ah well, you live and learn.)
Instead, we've built something which is much more verbose, but a lot cleaner as well: check what kind of input Python is giving us, extract exactly the information we need, parse it, perform the calculation, and return the result, with only one heap allocation for the final output (and a couple PyString allocations for FFI), rather than allocating coninuously for every new object.
The result, when applied across our three offending utility functions, is nearly half our remaining runtime gone. In default local runs without profiling, McFACTS now runs in under 20 seconds on a Mac M3 Max: some months back, the same run would take around 120 seconds on the same hardware.