This is the outline of a talk I originally gave at the September 24th RustNYC meetup. The slides are also available here.
Note that it is not a tutorial on how to begin using PyO3 for Rust-Python interop: my tutorial on that subject is here.
Welcome to Rust-Python Interop for Scientific Codebases!
Slide 4
When evaluating Rust-Python interop, we can ask two very pedantic questions. Why Rust, and why Python?
Slide 5
I’m sure everyone here has their own reasons for preferring Rust: you can also pick from the list up there (my favorite is the type system). But for our purposes, the main benefit is high-performance: we come to Rust because we want to speed up Python. So, why do we use Python?
Slide 6
Well, it’s ubiquitous, easy to learn, and uhhhhhh… lots of people say it’s a language with a lot of great features, and after four years of writing Python I cannot agree. But it's very easy to find people who know it, especially in scientific communities, and plenty of scientific libraries have been written for it, so here we are.
Slide 7
It's not the only language used in academia, though. Alternatives include:
-
R: a language widely used in scientific domains, especially the medical and social sciences, with built-in support for statistical operations, a professional, curated package distribution platform... and that's about it. I originally got into Rust-Python interop because I found an R library that I wanted to use, but faced with the prospect of opening up RStudio, I decided it might be less painful to rewrite it in Python. And then, faced with the prospect of rewriting an entire library in Python, I decided that it would be less painful to rewrite it in Rust first and then figure out some way to call it from a Jupyter notebook. The rest is history.
-
Julia: a high-performance programming language by academics, for academics, intended to replace both Python and R as the lingua franca of scientific programming and machine learning... which just never caught on. It's the awkward middle child in too many ways, and never quite got the traction it needed to take the world by storm.
-
FORTRAN: which is somehow still around. A lot of legacy scientific codebases still use it, or at least have to work around it, particularly in climate science, because they started programming their models in the 60s and never stopped. Its speed is the only thing that recommends it.
Slide 8
So, though Python may not be my favorite language, it's firmly in first place within this domain. But why would we need interoperation?
I'm going to be very unscientific for a moment and assert the following graph without evidence.
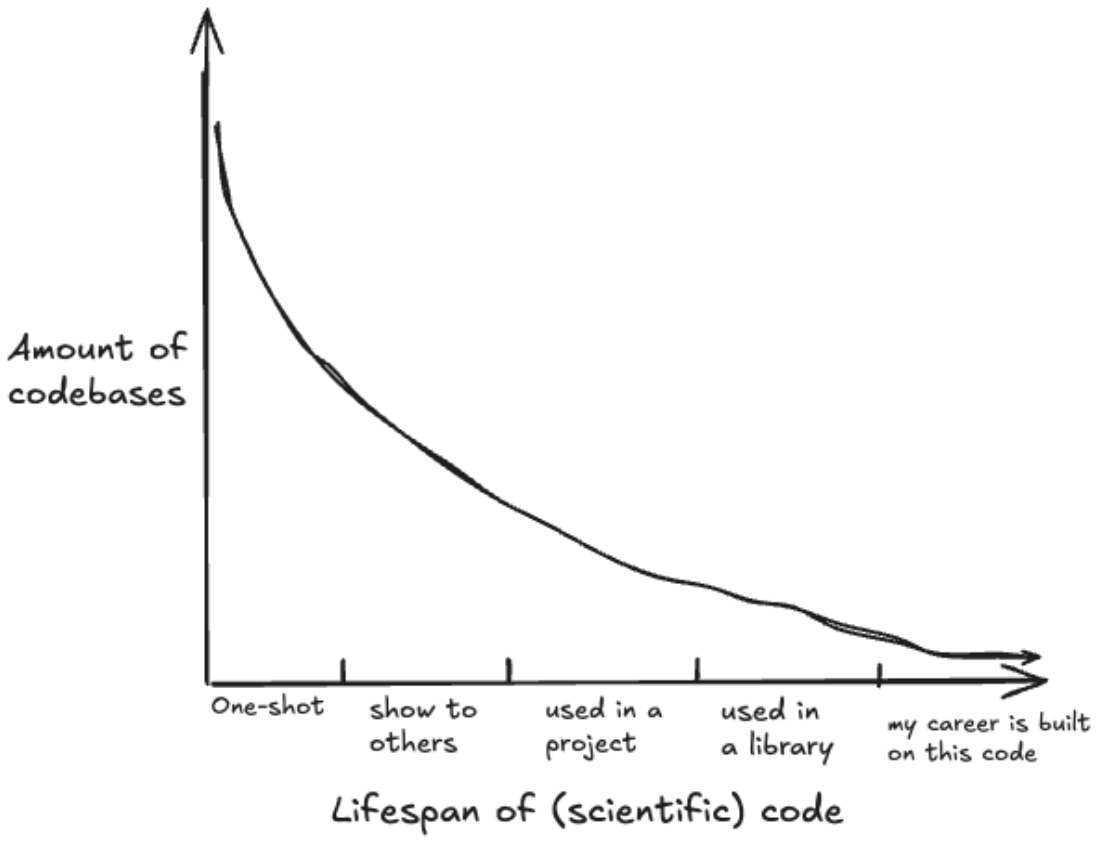
Most Python code in the scientific domains is short-lived, one-shot code. You do a quick calculation, plot a graph, and forget about it.
Sometimes you'll show it to a couple other people, who might copy it, and you make an effort to at least make it legible.
Some of that code actually gets used in a longer-term project. More rarely, it'll end up in a published library or package. And a very, very small proportion of overall code written will end up being the foundation of your career, and the careers of your colleagues and PhD students.
Slide 9
When we're on the left side of this graph, thinking about performance in any capacity is perverse. Even if you're typing from memory, you will spend orders of magnitude more time writing that matplotlib script than it will take to run. This is a scenario where you really do want to optimize for ease of use.
But as you travel right along this graph, the ratio of time spent writing to time spent running flips. At first, it's worthwhile to stick with what you know and what's comfortable. The costs of throwing out the code you've already written to rewrite it in a more performant language just aren't merited.
Slide 10
And then it happens. Overnight, you find that your library has thousands of users who've plugged into their own applications, and they're wondering why it's so goddamn slow.
You need performance and you need it yesterday. But a full rewrite just isn't in the cards: the codebase is too large and interconnected, and your students' PhD theses depend on introducing a new feature before October, and you're not a full-time software engineer. You just can't take weeks or months on a total rewrite.
Instead, you need a surgical intervention: identify the hot loop, the parts of the application that are really costing you time and memory, and rewrite those to a more performant language.
Slide 11
Now, there's plenty of options here, which should tell you how often this situation arises.
-
Numba: This is a relatively quick intervention in native Python. Just import Numba and sprinkle your codebase with some decorators, and you've sped up your hot loop with JIT compilation! Unfortunately, it's also a temperamental library with infamous version and dependency issues. Once you add it, it's hard to remove, and it limits your options down the line. As one developer put it to me, "once we use Numba, we'll be dancing around version conflicts for the rest of our lives".
-
Juliacall: while Julia as a primary language never took off, there are a good number of scientific libraries written with it, and we can call into them using the juliacall JIT. If there's a preexisting library that fits your needs, this is a great solution, though otherwise, you'll still need to rewrite to Julia yourself. That said, you do need to accept a little overhead from the JIT, and do some profiling to avoid some silly mistakes. I once saw a script which spent around 1/8th of its runtime building the JIT... because it was calling a script that imported juliacall and built a new instance of the JIT from scratch each time... inside a loop. This remains the funniest performance bug I've ever seen.
-
CPython: Just use the CPython API (more on this later) to optimize the code in C! This solution is as old as the hills, and people have been running away from it from just as long. Kudos to you if you want to do it, but prepare to spend a lot of time turning big refcounts into little refcounts.
-
cffi/uniffi: instead of using CPython directly, use runtime bindings like cffi or uniffi to write C code, and then bind that to Python code automatically, with no need to manually handle the CPython API. The downside to these is that they do require the end user to have the relevant bindings installed, which adds another layer of friction and potential version conflicts.
-
Cython, pybind11, PyO3: This is where we want to be: compile-time Python bindings for C, C++, and Rust respectively, which produce a Python wheel at the end of the process. You can just run the end product without ever knowing it was anything other than native Python, without needing to touch the CPython API.
As you can tell, the last option is what I prefer and advocate. But how do they actually work? How can we take a program in C, C++, or Rust, and make it walk and talk like a Python program? Let’s recap how Python itself executes.
Slide 12
For those unaware, Python is an interpreted language: Python code written by the user is not directly converted to binary, but to an intermediate bytecode representation, which resembles a list of commands.
These commands can call other bytecode, but to do any useful work (ie making, destroying, or modifying a Python object) they must eventually call a PyCFunctionObject. This connects into the CPython API, which will likely go through a few layers of calls before bottoming out in C code.
Now, there's a lot that we could say about this setup, but let's just start with the fact that it's actually quite convenient for us.
User-side Python doesn't really have any knowledge of what happens beyond the PyCFunctionObject call. It just sends in some information, expects to get some information out according to a calling convention, and expects that certain invariants (namely, the GIL) are preserved by whatever processes go on over there.
That means that, if we can learn to speak the CPython calling convention and don't mess with the GIL, we can just... insert ourselves at this stage and run whatever we want, and Python will be none the wiser.
Slide 13
Indeed, this is what PyO3 automates. We provide a PyCFunctionObject, but instead of calling into the CPython API, it calls into the PyO3 API, which validates the input data and ensures that we hold the GIL, and then hands off control to our precompiled Rust binary.
From that point on, we're home free, writing native Rust. However, this isn't a Rust talk, it's an interop talk, so I'm going to focus a little more on this API layer.
This also means that we can no longer proceed without discussing the Python memory model. Children and Haskell programmers are advised to cover their ears.
Slide 14
Now, if you're like me, you may have once been asked in an interview to describe the Python memory model, only to draw a complete blank. I assure you, it does exist.
Slide 15
This is because the first rule of the Python memory model is that the user should never, ever have to think about the Python memory model.
Now, there's a common saying in the Python community. Everything in Python is an __?
{signal for audience participation}
That's right, an O.B.J.E.C.T.!
Slide 16
Now, can anyone tell me what O.B.J.E.C.T. stands for?
{wait no more than 5 seconds for audience participation}
Slide 17
That's right, it stands for 'Reference-Counted Heap Allocated C Struct!
It's a terrible acronym, but they don't consult me on decisions like this.
Slide 18
When you get right down to it, Python is C wearing ten layers of trench coats. This, for example, is the C representation of an integer.
struct _longobject { long ob_refcnt; PyTypeObject *ob_type; size_t ob_size; long ob_digit; };
When we allocate a new integer, such as with
x = 257
We're allocating an 8-byte pointer on the stack, then allocating this _longobject on the heap. Inside it, we've got an 8-byte refcount--because you need ubiquitous refcounting if you want your user to never have to think about ownership--an 8-byte type pointer--because how else do you maintain dynamic typing at runtime--an 8-byte size counter--because that integer must be arbitrarily growable!--and finally, the 4-byte i32 payload itself.
Yes, that does mean that after taking padding into account, we've allocated 40 bytes across stack and heap for a 4-byte integer.
Oh, and the refcount, which is invalid if it is ever less than zero, is a signed integer. Just wanted to get that on the record.
Slide 19
Once again, there are a lot of things we could say about this setup... but one of them is that this is fairly convenient for us. This struct contains all the information we need to handle the FFI crossing. If our Rust function would ever clone or drop the object, we increment or decrement the refcount. We can use the type pointer to identify what kinds of Rust types it can be mapped to, including checking if it is a subclass of a known primitive, and use the size counter to ensure it will fit in the space provided.
Slide 20
Now, let's proceed with a simple example from a real Python codebase. This is from the McFACTS galaxy simulation project led by Saavik Ford, who was just recently voted in as the chair of the astrophysics department a CUNY.
def cubic_y_root(x0, y0): # Calculate the root of cubic function f(y) = x0*y^3 + 1.5*y - y0 coefficients = np.array([x0, 0, +1.5, -y0]) poly = np.polynomial.Polynomial(coefficients[::-1]) roots = poly.roots() return roots
We're calculating the root of a cubic function, and it looks pretty good to start. Very short, using numpy for the actual calculation, the roots() function is probably already optimized and backended in C.
Probably no need to backend this in Rust, right?
Sure... until we profiled this and found that an absurd amount of our total runtime was spent in here.
Any guess as to why?
{wait a few seconds for audience suggestions}
It's because the roots solver doesn't know or care what degree polynomial you're passing into it. It's a fully general eigenvector solver!
For large, degree-n polynomials which have no closed-form solution, this is a performant approach. But if we're solving a degree-3 polynomial--in fact, the same degree-3 polynomial each time--it's absurd overkill.
Slide 21
We can easily write up a closed-form solution with Cardano:
def cubic_y_root_cardano(x0, y0): """ Optimized version of cubic_y_root using an analytic solver. Solves the equation: x0*y^3 + 1.5*y - y0 = 0 """ # handle the edge case where x0 is zero, becomes 1.5*y - y0 = 0 if x0 == 0: return np.array([y0 / 1.5]) # convert to the standard depressed cubic form y^3 + p*y + q = 0 # by dividing the original equation by the leading coefficient x0 p = 1.5 / x0 q = -y0 / x0 # calculate the discriminant term to see if there will be one or three real roots delta = (q/2)**2 + (p/3)**3 if delta >= 0: # discriminant positive or 0, one real root, two complex roots sqrt_delta = np.sqrt(delta) u = np.cbrt(-q/2 + sqrt_delta) v = np.cbrt(-q/2 - sqrt_delta) roots = np.array([u + v]) else: # discriminant negative, three real roots term1 = 2 * np.sqrt(-p / 3) phi = np.arccos((3 * q) / (p * term1)) y1 = term1 * np.cos(phi / 3) y2 = term1 * np.cos((phi + 2 * np.pi) / 3) y3 = term1 * np.cos((phi + 4 * np.pi) / 3) roots = np.array([y1, y2, y3]) return roots
Which bypasses the matrix initialization and operations in favor of directly computing the solution.
This is also red meat for a Rust conversion: it's a leaf function that takes in and outputs common primitives, calls only simple functions with core library equivalents, doesn't mutate external state, and performs single-threaded, CPU-bound computations. As far as Rust-Python translation goes, this one's like shooting fish in a barrel. I had to go ahead and make this implementation heapless just to avoid boredom.
#[pyfunction(signature = (x0, y0))] pub fn cubic_y_root_cardano(x0: f64, y0: f64) -> ([f64; 3], usize) { if x0 == 0.0 { ([y0/1.5, 0.0, 0.0], 1) //padding out the array } else { let p = 1.5/x0; let q = -y0/x0; let delta = (q/2.0).powi(2) + (p/3.0).powi(3); if delta > 0.0 { // one real root path let sqrt_delta = delta.sqrt(); let u = (-q/2.0 + sqrt_delta).cbrt(); let v = (-q/2.0 - sqrt_delta).cbrt(); ([u + v, 0.0, 0.0], 1) //padding out the array } else { // three real roots path let term1 = 2.0 * (-p / 3.0).sqrt(); let phi = ((3.0 * q) / (p * term1)).acos(); let y1 = term1 * (phi / 3.0).cos(); let y2 = term1 * ((phi + 2.0 * PI) / 3.0).cos(); let y3 = term1 * ((phi + 4.0 * PI) / 3.0).cos(); ([y1, y2, y3], 3) } } }
Slide 22
And we see that this does, in fact, get us large performance benefits (or more accurately, we're no longer wasting runtime on unnecessary operations in a hot loop).
Polynomial.roots: 15.80 microseconds/call 1.0x
Python (Analytical): 1.77 microseconds/call 8.92x
Rust-Python (Analytical): 0.37 microseconds/call 46.47x
With this kind of speedup, this has got to be running in production right now, right?
Wrong.
Why not? I'm going to make like a CPU and address that at a later time.
Slide 23
Here's another example from the same codebase: it's more recent, so I still have screenshots of the profiler output.
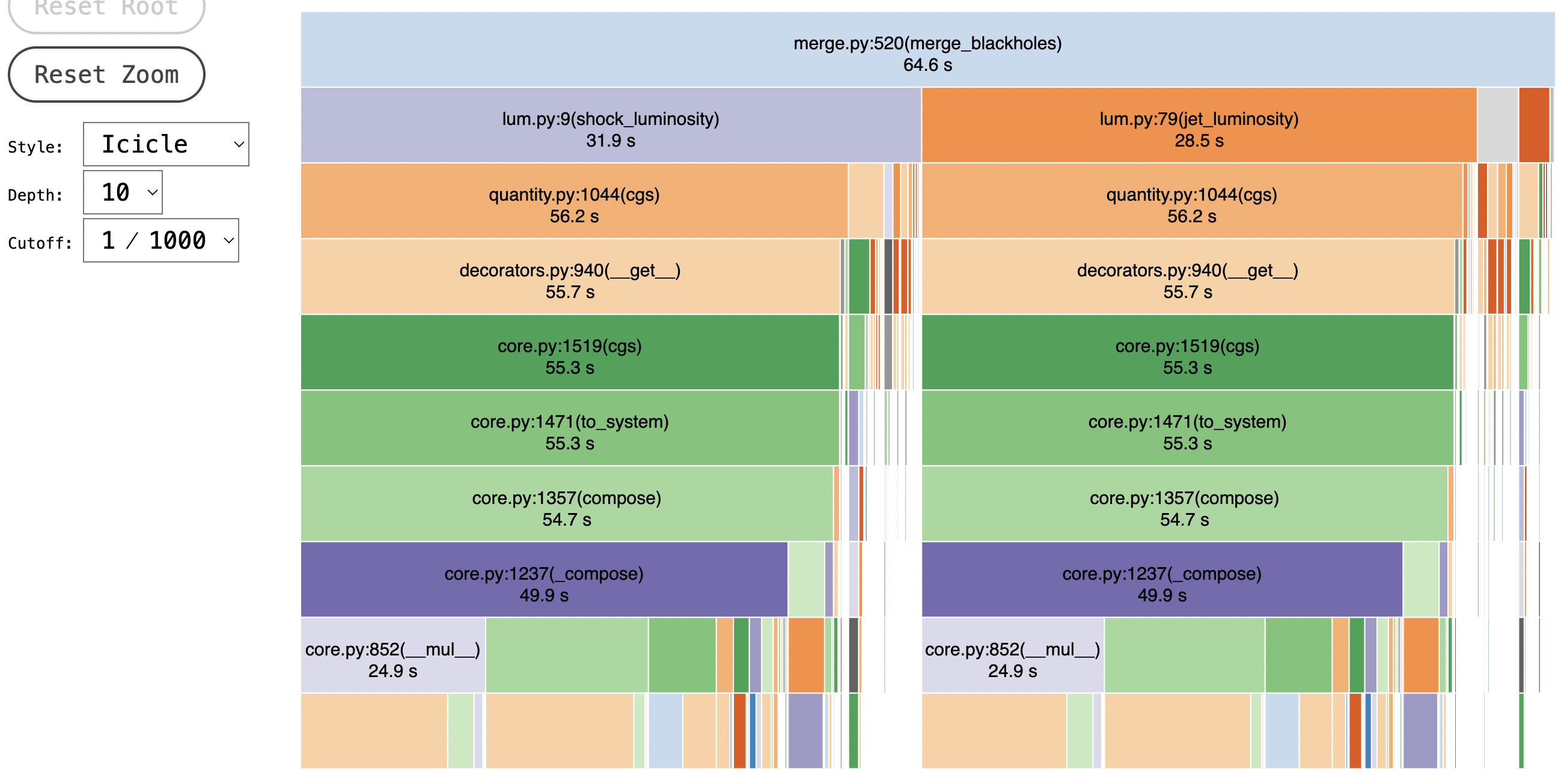
In this case, we have a merge_blackholes function, whose runtime is dominated by luminosity calculations. This is a little suspicious to begin with, more so when we see that the two luminosity functions are taking up very similar amounts of time... even though they should run the same number of times, and one is much shorter than the other.
Slide 24
When we look at the profiler details, we find that one of these functions, shock_luminosity, is taking almost 15 milliseconds per call.

Slide 25
What's actually going on in this function?
r_hill_rg = bin_orb_a * ((mass_final / smbh_mass) / 3)**(1/3) r_hill_m = si_from_r_g(smbh_mass, r_hill_rg) r_hill_cm = r_hill_m.cgs disk_height_rg = disk_aspect_ratio(bin_orb_a) * bin_orb_a disk_height_m = si_from_r_g(smbh_mass, disk_height_rg) disk_height_cm = disk_height_m.cgs v_hill = (4 / 3) * np.pi * r_hill_cm**3 v_hill_gas = abs(v_hill - (2 / 3) * np.pi * ((r_hill_cm - disk_height_cm)**2) * (3 * r_hill_cm - (r_hill_cm - disk_height_cm))) disk_density_si = disk_density(bin_orb_a) * (u.kg / u.m**3) disk_density_cgs = disk_density_si.cgs msolar = ct.M_sun.cgs r_hill_mass = (disk_density_cgs * v_hill_gas) / msolar # for scaling: rg = ct.G.cgs * smbh_mass * ct.M_sun.cgs / ct.c.cgs
Well, we're multiplying an array by a scalar. And then multiplying another array by another scalar. And then, just for some variety, we're transforming an array and multiplying it by itself! Thrilling stuff.
There's nothing in here that should be taking 15 milliseconds: it should be closer to 15 microseconds.
So where is this performance suck coming from?
Slide 26
Look back at the visualization: both luminosity functions are dominated by calls to 'quantity.py' which itself is dominated by calls into 'decorators.py'. Specifically, a __get__ dunder method.
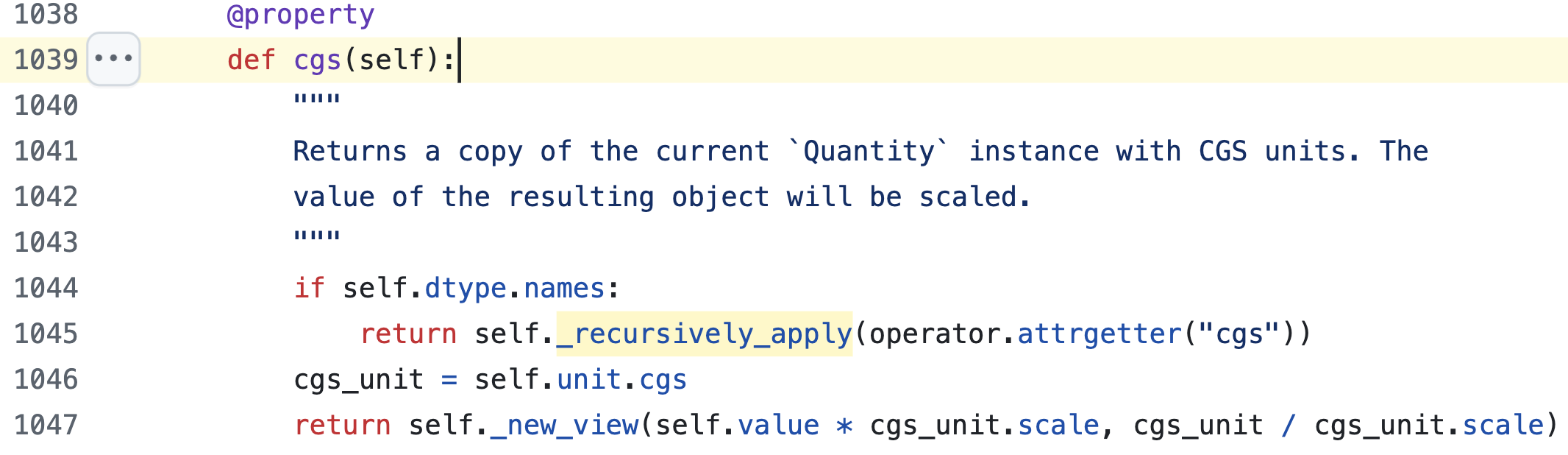
Turns out, the culprit is from astropy's unit conversion library. As best as I can tell, each surface call results in recursive calls to multiple other objects scattered around memory to check if they possess units. Each individual call is fast... but the explosive growth in the number of calls results in around a million objects being scanned across an entire run, with all the wasteful memory calls and overhead that entails.
Slide 27
How would we fix this in Rust?
Unlike the last example, this is non-trivial to translate. We'll need to bring in some handling for unit conversion, either writing our own or using the uom crate. But more importantly, we're not just taking in primitives anymore. Two of the functions called in the body are python lambdas passed in as arguments, which are determined at runtime in an entirely separate part of the codebase.
So we need to be a bit more involved: instead of a surgical, single-point intervention, we'll also need to modify the section that generates the lambdas to create a stateful Rust struct: we can then store and pass its Python representation in as an argument to our new Rust-Python barrier function, which will need to do some more work to validate inputs and outputs, and, and, and...
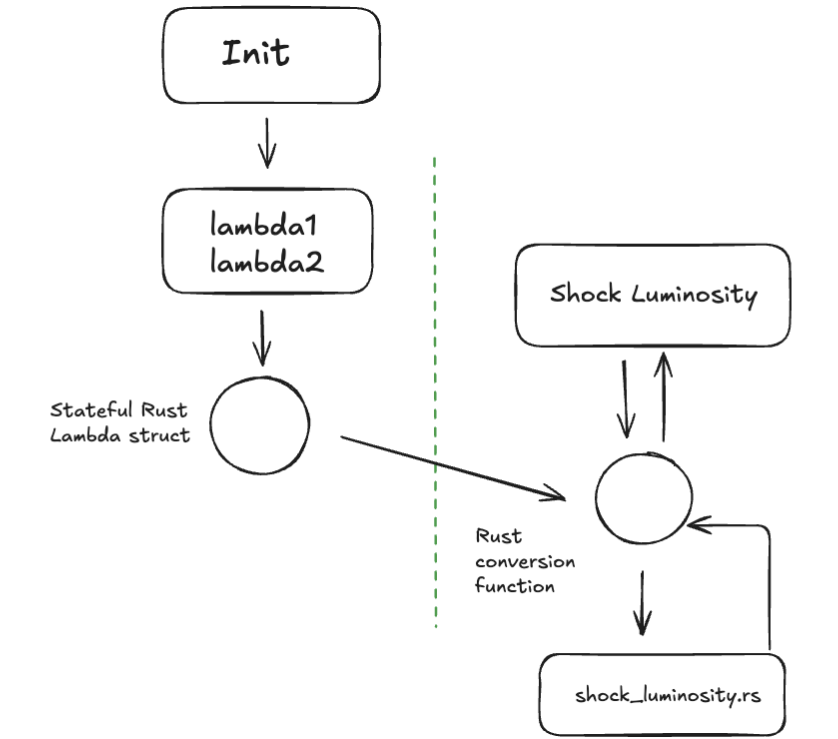

And by the time I diagrammed it out, the devs had fixed it.
Slide 28
They just removed the offending unit conversions and handled them manually, which is apparently doable if you 'wrote the original code' and 'have a PhD in the subject domain'.
Who could have guessed?
This cut the merge_blackholes runtime cost by 90% and cut runtime for the entire script by a third.
29
This is a mindset change that you need to internalize before contributing to scientific codebases as a non-domain-specialist: you're likely coming from a domain where you're the star, or at least perceive yourself as such. You write the beating heart of an application, or train core models, or coordinate millions and billions of requests without losing sight of a single sparrow.
You're the hotshot, code-spitting cowboy! Well, not here.
A scientific codebase and its maintainers does not care about any of that. They care about correctness (because it's very difficult to tell whether the results of a simulation are correct), comprehensibility (aka, the domain experts need to be able to understand the code at a glance) and timeliness (aka, this needs to be ready for my student's PhD defense in October).
Performance, important though it is, will never supercede these requirements, and if your interventions do not serve those ends, you are a net negative for the project.
This is why, for all the speedups that Rust could give us, we're not rushing to rewrite even a small part of it, at least not yet. There's too many remaining opportunities to optimize by making small adjustments to the native Python and adjusting the algorithms, and that's where our energy needs to go. The benefits from rewriting to other languages, though not insubstantial, are not yet worth the increased complexity compared to working on the native Python.
Further down the line, when the simulation is polished until it shines and we've plucked all the low-hanging fruit for optimization, that's when I'll come in with a list of proposed rewrites, designed to slot directly into the currently existing codebase with full testing and minimal changes to the API, the inputs, or the outputs: it should be all-but invisible.
On that day, we'll be reaping the benefits of targeted Rust-Python interoperation. But it is not this day.