For the latest batch of optimizations speeding up/replacing AstroPy unit operations in McFACTS (expect my next blog post titled The Agony and the Ecstasy of AstroPy Units), I've wound up just extracting the string representation of the unit type and matching on it directly:
fn extract_unit(ob: &Bound<'py, PyAny>) { // extract unit value let unit_obj = ob.getattr("unit")?; // use python method to extract string representation let binding = unit_obj.call_method0("to_string")?; let unit_str: &str = binding.extract()?; match unit_str.as_bytes() { b"kg" | b"kilogram" => return Ok(Unit::Kilogram), b"t" | b"tonne" => return Ok(Unit::MetricTon), b"earthMass" | b"M_earth" => return Ok(Unit::EarthMass), b"jupiterMass" | b"M_jup" => return Ok(Unit::JupiterMass), b"solMass" | b"Msun" => return Ok(Unit::SolarMass), b"m" | b"meter" => return Ok(Unit::Meter), // _ => {... fallback to PHF} }
But then I wondered whether matching on bytes would actually do anything different compared to just matching on the string literals themselves. After all, a Rust &str is a fixed-length collection of utf-8 encoded bytes. It would stand to reason that they'd probably just end up doing the same thing, right? Maybe my byte-matching was just making it less readable for no benefit.
So I tried to look up blog posts about the performance differences between string and byte matching in Rust... and really couldn't find anything? Maybe I'm just looking in the wrong place or using the wrong keywords, but I couldn't for the life of me find a blog post or forum discussing it.
Thus disappointed, I jumped over to Compiler Explorer to check things out myself.
#[inline(never)] pub fn foo( input: &str ) -> u8 { match input { "foo" => { 1 } "bar" => { 2 } "baz" => { 3 } _ => { 4 } } } #[inline(never)] pub fn bar( input: &str ) -> u8 { match input.as_bytes() { b"foo" => { 1 } b"bar" => { 2 } b"baz" => { 3 } _ => { 4 } } }
The former compiles (with Rust 1.94.0 -O) to the following:
example::foo::h36f50a3b184c6687:
mov al, 4
cmp rsi, 3
jne .LBB0_6
movzx eax, word ptr [rdi]
xor eax, 28518
movzx ecx, byte ptr [rdi + 2]
xor ecx, 111
or cx, ax
je .LBB0_2
movzx eax, word ptr [rdi]
xor eax, 24930
movzx ecx, byte ptr [rdi + 2]
xor ecx, 114
or cx, ax
je .LBB0_4
movzx eax, word ptr [rdi]
xor eax, 24930
movzx ecx, byte ptr [rdi + 2]
xor ecx, 122
or ecx, eax
cmp cx, 1
mov al, 4
sbb al, 0
.LBB0_6:
ret
.LBB0_2:
mov al, 1
ret
.LBB0_4:
mov al, 2
ret
And the latter to the following:
example::bar::h6f084f2e00ba518e:
mov al, 4
cmp rsi, 3
jne .LBB0_6
movzx ecx, byte ptr [rdi]
cmp ecx, 98
je .LBB0_4
cmp ecx, 102
jne .LBB0_6
movzx eax, byte ptr [rdi + 1]
movzx ecx, byte ptr [rdi + 2]
xor al, 111
xor cl, 111
xor edx, edx
or cl, al
setne dl
lea eax, [rdx + 2*rdx]
inc eax
ret
.LBB0_4:
cmp byte ptr [rdi + 1], 97
jne .LBB0_6
movzx eax, byte ptr [rdi + 2]
cmp al, 122
sete cl
mov dl, 4
sub dl, cl
cmp al, 114
movzx ecx, dl
mov eax, 2
cmovne eax, ecx
.LBB0_6:
ret
They're around the same length, but the implementations are pretty dang different!
The former is a straightforward linear string match. It loads the input, does an exact match against "foo", then against "bar", then against "baz".
Prior to the comparisons, it checks the length: since all match strings are length 3, if the length isn't 3, we can exit immediately with the wildcard result.
Assuming this doesn't happen, it then performs the string comparisons one at a time, loading the first two bytes, checking, then the third byte, and checking. Once it either finds an exact match or exhausts all possibilities, it returns the appropriate value. If the input happens to be an unmatched length-3 string, like 'quz', then we get the most pessimistic outcome, testing against all possible match arms even though it doesn't share a prefix with any of the matches.
There's a little computation trickery going on in the final "baz" vs wildcard case to eliminate another branch, using the sbb instruction (I didn't even know this thing existed!) to get compute the final result with control flag math... which is kinda wild, but is only possible as an optimization because of the particular output values we used, and doesn't generalize.
You'll also note that the "bar" and "baz" comparisons both repeat xor eax, 24930, which compares the first two bytes to "ba". This is a missed opportunity: "bar" and "baz" share a prefix, so if we know that the first two bytes aren't "ba", then we've ruled out both of them and can return the wildcard immediately. But this comparison implementation doesn't make that optimization, instead making all the comparisons even if they would be redundant.
But the byte comparison implementation? Oh boy does it implement that optimization.
The byte comparison implements a trie in just 33 lines of assembly. I'm far from fluent in assembly, so I made a little sketch to illustrate it:
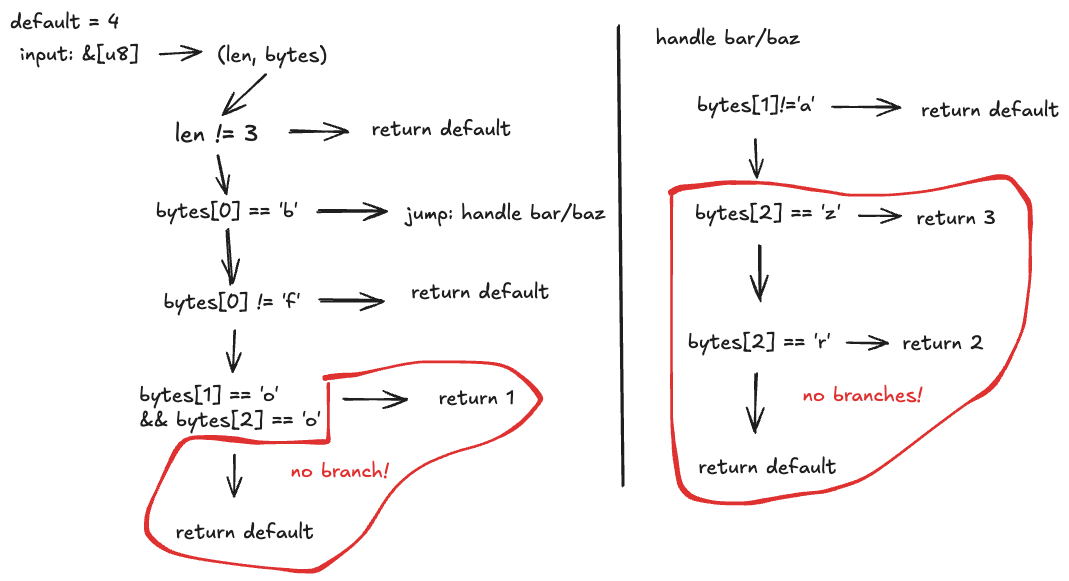
Like the string comparison, it starts with a length check: if it's not length 3, return the wildcard. But then, it checks if the first byte is 'b': if so, it jumps to a separate block to handle the "bar"/"baz" branch.
It then checks if the first byte is 'f', and if so, then goes ahead and checks if the remaining bytes are 'o' and 'o' (since we've already established that the input must be 3 characters long, this is sufficient). If any of these would fail, we instead return the wildcard.
In the 'b' block, on the other hand, we check if the second byte is 'a' (if not, return default), and then whether the third and final byte is 'r' or 'z', returning the appropriate output or wildcard.
It's pretty interesting that these optimizations can be made on byte slices, but not on strings. Not quite sure why that should be the case.
Even more interesting is some of the trickery it uses to minimize the number of branches.
In the 'f' case, it uses a control flag and some arithmetic to compute the final output rather than branching.
movzx eax, byte ptr [rdi + 1] ; load bytes[1]
movzx ecx, byte ptr [rdi + 2] ; load bytes[2]
xor al, 111 ; 'o': 0 if match
xor cl, 111 ; 'o': 0 if match
xor edx, edx ; let edx = 0
or cl, al ; set control flag to 0 iff al == 0 && cl == 0
setne dl ; dl = 0 if "foo", 1 if not
lea eax, [rdx + 2*rdx] ; eax = dl * 3 → 0 or 3
inc eax ; eax++, 1 ("foo") or 4 (default)
In the 'b' case, it actually calculates all three remaining possibilities (2, 3, 4) and selects between them using the cmovne (conditional move not equal) instruction.
movzx eax, byte ptr [rdi + 2] ; load bytes[2]
cmp al, 122 ; 122 = 'z'
sete cl ; cl = 1 if 'z', else 0
mov dl, 4
sub dl, cl ; dl = 3 if 'z', 4 if not
cmp al, 114 ; 114 = 'r'
movzx ecx, dl ; ecx = the "baz" result (3 or 4)
mov eax, 2 ; eax = 2 (the "bar" result)
cmovne eax, ecx ; if byte[2] != 'r': use the baz/default value
Once again, pretty damn wild, but this is just because I chose outputs from 1 to 4, which don't generalize.
But is byte matching any faster?
According to some quick and dirty benchmarks, yes.
As always, caveat optimizer, your mileage may vary, benchmark on your own application and domain first. But using criterion, large chunks of randomized input, and some junk work to evict caches, it does seem like there are some real differences.
When testing on the possible inputs 'foo', 'bar', 'baz', 'qux', 'zip', 'dog', 'cat', 'xyz', and 'unknown', we found that byte-matching was pretty reliably ~2x faster, with very narrow ranges:
foo_str_match_mixed time: [6.5353 µs 6.5375 µs 6.5399 µs]
Found 6 outliers among 100 measurements (6.00%)
3 (3.00%) low mild
3 (3.00%) high mild
bar_bytes_match_mixed time: [3.1134 µs 3.1296 µs 3.1478 µs]
This is for chunks of length 4096, so these average to 1.60 nanoseconds and 0.76 nanoseconds per-element respectively. All but the last case are length-3 strings, so most of the non-matches are not being caught early by the length check. Rather, it seems that the trie is able to more quickly match legitimate inputs with the 'ba' prefix, and also more quickly eliminate invalid inputs, which do not share prefixes with the legitimate inputs.
Here are the full benchmarks, run locally on a Mac M3 Max, with the changes and outliers abridged:
foo_str_match/foo time: [997.18 ps 998.08 ps 999.08 ps]
foo_str_match/bar time: [1.0016 ns 1.0051 ns 1.0092 ns]
foo_str_match/baz time: [1.0609 ns 1.0634 ns 1.0657 ns]
foo_str_match/qux time: [1.0620 ns 1.0639 ns 1.0655 ns]
foo_str_match/zip time: [1.0678 ns 1.0691 ns 1.0708 ns]
foo_str_match/dog time: [1.0627 ns 1.0642 ns 1.0655 ns]
foo_str_match/cat time: [1.0615 ns 1.0629 ns 1.0642 ns]
foo_str_match/xyz time: [1.0682 ns 1.0700 ns 1.0723 ns]
foo_str_match/unknown time: [996.66 ps 996.93 ps 997.22 ps]
bar_bytes_match/foo time: [610.23 ps 614.77 ps 620.33 ps]
bar_bytes_match/bar time: [617.31 ps 619.39 ps 621.72 ps]
bar_bytes_match/baz time: [614.00 ps 616.48 ps 619.13 ps]
bar_bytes_match/qux time: [530.63 ps 531.88 ps 533.09 ps]
bar_bytes_match/zip time: [520.48 ps 522.76 ps 525.15 ps]
bar_bytes_match/dog time: [525.06 ps 526.81 ps 528.53 ps]
bar_bytes_match/cat time: [524.35 ps 526.49 ps 528.41 ps]
bar_bytes_match/xyz time: [533.28 ps 534.80 ps 536.25 ps]
bar_bytes_match/unknown time: [275.48 ps 276.69 ps 277.92 ps]
foo_str_match_mixed time: [6.9018 µs 6.9224 µs 6.9416 µs]
bar_bytes_match_mixed time: [3.3932 µs 3.4086 µs 3.4219 µs]
The 'mixed' benchmarks at the bottom represent the randomized, cache-polluted checks on 4096-long inputs, while the rest are each individual function's performance on matching a single deterministic input. The individual case benchmarks are less representative of actual performance in real world cases, but still broadly match what we see in the more rigorous case: while the strig-matching function hovers around 1 nanoseconds for all inputs, the byte matching function shows some more variance, hovering around the 500-600 picosecond range (0.5-0.6 nanoseconds).
Especially interesting is that, while both functions should be discriminating the 'unknown' case immediately based on the length check, the string-matcher is taking nearly a full nanosecond on it, while the byte-matcher is exiting early, in under 300 picoseconds.
Now, I'm running this locally on ARM, not x86-64, so I went and got the asm for each function:
bytematch on master [?] is 📦 v0.1.0 via 🦀 v1.94.0 took 50s
❯ cargo asm --lib "foo"
Finished `release` profile [optimized] target(s) in 0.01s
.globl bytematch::foo
.p2align 2
bytematch::foo:
Lfunc_begin1:
.cfi_startproc
cmp x1, #3
b.ne LBB1_4
ldrh w8, [x0]
ldrb w9, [x0, #2]
mov w10, #28518
cmp w8, w10
mov w8, #111
ccmp w9, w8, #0, eq
b.eq LBB1_5
ldrh w8, [x0]
ldrb w9, [x0, #2]
mov w10, #24930
cmp w8, w10
mov w8, #114
ccmp w9, w8, #0, eq
b.eq LBB1_6
ldrb w8, [x0, #2]
ldrh w9, [x0]
orr w8, w9, w8, lsl #16
rev w8, w8
mov w9, #31232
movk w9, #25185, lsl #16
cmp w8, w9
cset w8, hi
csinv w8, w8, wzr, hs
cmp w8, #0
mov w8, #3
cinc w0, w8, ne
ret
LBB1_4:
mov w0, #4
ret
LBB1_5:
mov w0, #1
ret
LBB1_6:
mov w0, #2
ret
bytematch on master [?] is 📦 v0.1.0 via 🦀 v1.94.0
❯ cargo asm --lib "bar"
Finished `release` profile [optimized] target(s) in 0.00s
.section __TEXT,__text,regular,pure_instructions
.globl bytematch::bar
.p2align 2
bytematch::bar:
Lfunc_begin0:
.cfi_startproc
cmp x1, #3
b.ne LBB0_6
ldrb w8, [x0]
cmp w8, #98
b.eq LBB0_4
cmp w8, #102
b.ne LBB0_6
ldrb w8, [x0, #1]
ldrb w9, [x0, #2]
cmp w9, #111
mov w9, #111
ccmp w8, w9, #0, eq
mov w8, #4
csinc w0, w8, wzr, ne
ret
LBB0_4:
ldrb w8, [x0, #1]
cmp w8, #97
b.ne LBB0_6
ldrb w8, [x0, #2]
cmp w8, #122
mov w9, #3
cinc w9, w9, ne
mov w10, #2
cmp w8, #114
csel w0, w10, w9, eq
ret
LBB0_6:
mov w0, #4
ret
Both of these functions clearly do have the length check, that's the
cmp x1, #3
b.ne LBB**
at the start of each. I don't know where this discrepancy is coming from, but it's probably some really low-level detail about alignment or something. Down here in the sub-nanosecond range, we're at the mercy of hardware implementation details.
So, all things considered, I'm pretty happy to call this a victory for explicit byte-matching. Even in a toy case like this one, the byte-matching trie delivers a definite performance improvement, which I expect would be even larger in a more complex case with a larger number of possible matches with shared prefixes, and especially if we expected a non-trivial amount of our inputs to be unmatched.