A few days ago I read Micah Kepe's jsongrep is faster than {jq, jmespath, jsonpath-rust, jql}. There, he promoted an approach to high-performance JSON querying using DFAs generated by a regex-inspired JSON query language, with seriously impressive benchmarks to boot.
As so often happens, I wondered 'how can I get my old data science pals to use this?' and because I am a river to my people, decided to make Python bindings for jsongrep.
However, I ran into two problems.
First, the name jsongrep is already taken on PyPI by a v0.1.1 package from 2010. Ugh.
Second, jsongrep was only built to support in-memory queries. For most JSON, that's fine, especially since the original repo was a CLI tool first. But in the year of our Lord 2026, when we have datasets the size of Texas and RAM prices are shooting through the roof, it seems impolite to not support out-of-memory querying. If the JSON won't fit in RAM, jsongrep can't query it!
So instead of just writing bindings and pushing to PyPI, I decided to dive a little deeper and reconfigure jsongrep's internals to suit my own needs.
Meet crowley
The result was crowley, a Rust crate (with Python bindings, natch) built to apply jsongrep's efficient DFA search over JSON events streaming out of memory.
Its use case is fairly narrow: it lets you query files (and raw strings, but really it's meant for files) without first loading them into memory, so long as your query can be expressed using Kepe's jsongrep regular expression language (which, as I think about it, really needs a name).
Within those bounds, it performs very well. The main point of comparison here is ijson, an iterative JSON parser powered by the yajl C engine.
As it developed, I figured that it was worthwhile to put in a lot more polish and make crowley not just powerful, but also nice and ergonomic from the Python end. Despite how common it is, ijson is remarkably simple and feature-sparse. You can search one file at a time by JSON prefixes... and that's kinda it? All other functionality is built on top of it by processing the iterator stream manually.
Aside from ijson, there are some other relevant Python packages that offer out-of-memory JSON querying, like pandas, polars, and duckdb.
But unlike crowley or ijson these are not dedicated, specific JSON query engines: they're dataframe/database libraries that have methods to lazily process JSON into a more regular, organized, and easily-queryable format. This is great, especially for JSON you'll be analyzing repeatedly... but even with efficient lazy loading, you're still spending a good deal of up-front time and work on that transformation before you get to make a single query.
Moreover, they're a good deal more fragile, since they all need to tranform the JSON into a format that fits their own schemas. They're pretty smart about this: duckdb in particular is notable for its automatic schema discovery. But they can still choke on data whose schema is unstable or inconsistent. You know. JSON.
crowley intends to provide a richer, more featureful, and more performant alternative to ijson for querying out-of-memory JSON, without needing to transform the data into a certain schema. This is especially useful in cases where the data is transient, requiring just a handful of queries that don't merit a full database transformation.
How it Started
I started with an off-the-shelf SAX-style JSON event parser, json-event-parser. I then created a new engine that would drive the original DFA query using parser events rather than values.
Early benchmarking showed that we were in the same general ballpark as ijson, our main use-case competitor: we took up slightly less memory, but were reliably 40-60% slower.
Some optimizations to the engine, reducing allocations during DFA querying, and speeding up json-event-parser's whitespace processing sped it up massively. Right now, we're either slightly faster than ijson (on simple queries that are just returning raw values) or 2-3x faster for queries where we can avoid materializing subtrees or where we can take advantage of more expressive query structures.
How it's Going
Now, my benchmarks aren't nearly as thorough or nicely-formatted as Kepe's were in the original article. But I also don't want to further delay release to complete them. Improved performance is one of the big reasons to switch to crowley, but it's not the only one: superior power, flexibility, and expressivity are also important. So for the moment, I'm going to put down what I currently have, and in the future I'll put together a proper collection of benchmarks that are easy to run locally.
File: Flat GitHub log data, 34GB
Query: [*].repo.name
Count matches:
crowley: 71.6s
ijson: 128.8s
Difference: 1.8x
Return matches:
crowley: 116.0s
ijson: 126.1s
Difference: 1.09x
Return unique values:
crowley: 125.7
ijson: 129.5s
Difference: 1.03x
Return unique count:
crowley: 122.1
ijson: 129.5s
Difference: 1.06x
File: Nested GeoJSON, 30MB
Query: features[*].properties.name
Count matches:
crowley: 138.44ms
ijson: 421.85ms
Difference: 3.0x
Existence check (true):
crowley: 16µs
ijson: 793µs
Difference: 49x
Query: features[*].properties.scalerank
Sum matches:
crowley: 184.88ms
ijson: 425.89ms
Difference: 2.3x
Query: features[*].properties.nonexistent
Existence check (false):
crowley: 138.9ms
ijson: 409.7ms
Difference: 2.9x
Because of how restrictive ijson's queries are, our comparison queries aren't taking advantage of the query language's power. Even so, we can see that, in the worst case scenario, crowley is only slightly faster than ijson. This is when we're just returning values or filtering returned values for uniqueness.
But when materialization of values can be avoided, such as when we're counting matches, aggregating over numeric values, or checking or the existence of values, we can be 2-3x faster. In trivial cases such as checking for the existence of values that are found in the first chunk, the 'speedup' can be even larger, but this just represents crowley starting up faster than ijson.
But the real benefit comes from crowley's more expressive query language, which can efficiently express what would otherwise require Python loops aroung ijson.
It can extract multiple fields through disjunctions (at one or multiple levels) in a single pass without having to materialize the parent object:
# get the number of matching objects # 133.6ms crowley.Query(file_str, "features[*].properties.(name | admin)").count() # get the number of unique matches # 144.2ms crowley.Query(file_str, "features[*].properties.(name | admin)").unique_values() # get the number of matching objects # 851.6ms def ijson_two_passes(): with open(file_str, "rb") as f: count1 = sum(1 for _ in ijson.items(f, "features.item.properties.name")) with open(file_str, "rb") as f: count2 = sum(1 for _ in ijson.items(f, "features.item.properties.admin")) return count1 + count2 ijson_two_passes() # get the number of unique matches # 430ms def ijson_two_fields(): names = set() with open(file_str, "rb") as f: for obj in ijson.items(f, "features.item.properties"): if "name" in obj: names.add(obj["name"]) if "admin" in obj: names.add(obj["admin"]) return names ijson_two_fields()
It can extract all property values without internal iteration:
# get the number of all matching property values by query # 133.9ms crowley.Query(file_str, "features[*].properties.*").count() # get the number of all matching properties by internal iteration # 427.9ms def ijson_all_props(): count = 0 with open(file_str, "rb") as f: for obj in ijson.items(f, "features.item.properties"): count += len(obj) return count ijson_all_props()
It can select ranges of array elements without manual index checking:
- Note: this is one of the few places
crowleycan be slower under some conditions: if the array range is not at the root level,ijson+ Python break logic can stop more quickly, whilecrowleymust continue parsing the outer structure. For root-level array ranges,crowleyremains faster. Attempting to use the same approach withcrowleyas withijson, manually checking values and breaking out, makes crowley even slower, however.
Root-level array (github_array.json):
crowley [0:3]: 22µs (crowley terminates early more quickly)
ijson [0:3]+break: 234µs
Difference: 10.6x
crowley [97:102]: 464µs (crowley terminates early more quickly)
ijson [97:102]+break: 923 µs
Difference: 1.98x
crowley [*] (full): 49.4ms
crowley [*]+break: 60.9ms
Nested array (ne_10m.json):
crowley [0:3]: 131.4ms
ijson [0:3]+break: 847µs (ijson is able to short-circuit faster!)
Difference: 0.006x
crowley [97:102]: 133.8ms
ijson [97:102]+break: 11.5ms (ijson is able to short-circuit faster!)
Difference: 0.086x
# start of array crowley.Query(file_str, "features[0:3].properties.name", no_seek=True).values() # middle of array crowley.Query(file_str, "features[97:102].properties.name", no_seek=True).values() def ijson_range_start(): result = [] with open(file_str, "rb") as f: for i, name in enumerate(ijson.items(f, "features.item.properties.name")): if i < 3: result.append(name) else: break return result ijson_range_start() def ijson_range_mid(): result = [] with open(file_str, "rb") as f: for i, name in enumerate(ijson.items(f, "features.item.properties.name")): if 97 <= i < 102: result.append(name) if i >= 101: break return result ijson_range_mid()
And can even descend recursively in a way that ijson simply cannot do: this would require a non-streaming solution like json that loads the whole file into memory.
# get unique values of 'type' at any depth # 221.8ms : ['FeatureCollection', 'name', 'Feature', 'Polygon'] crowley.Query(file_str, "(* | [*])*.type", no_seek=True).unique_values() # get count of all matching objects at all depths # 156.7ms : 17090 crowley.Query(file_str, "(* | [*])*.type", no_seek=True).count() # walk the entire json tree manually looking for matching keys # 509.8ms import json def json_recursive_search(key): with open(file_str) as f: data = json.load(f) results = [] def walk(obj): if isinstance(obj, dict): for k, v in obj.items(): if k == key: results.append(v) walk(v) elif isinstance(obj, list): for item in obj: walk(item) walk(data) return results values = json_recursive_search("type") unique = set(str(x) for x in values)
Is there an audience for this?
Let me answer that with a graph:
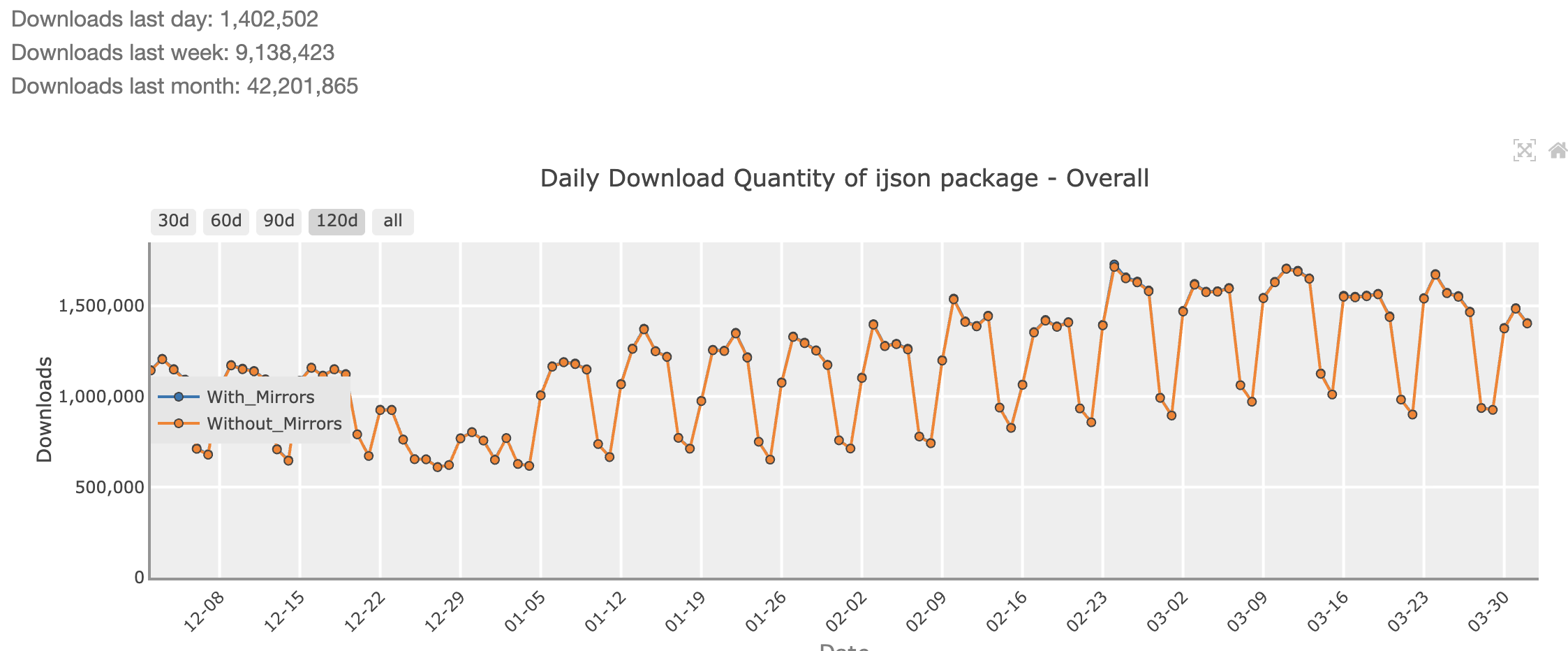
ijson gets downloaded roughly 42 million times a month. For reference, pandas gets downloaded around 500 million times a month, and numpy is downloaded over 800 million times a month.
So I wouldn't go as far as to say that ijson is ubiquitous, but even so, 5% of numpy's numbers is a LOT.
It's also a sight more than jq at 5M/month, or duckdb at 34M/month. It's comparable to polars at 47M/month. Based on how regular the import pattern is, it looks to me that more than a few enterprises have ijson running on a ton of servers, re-installing it constantly. All of them could benefit by switching to crowley (a lot of them could probably benefit more from switching to other tools, but ijson -> crowley is a much easier workflow switch than to pandas or duckdb).
You'd gain a considerable speedup, slightly reduced memory usage, and a lot more flexibility.
Say goodbye to
sum(float(x) for x in ijson.items(file, "users.item.age"))
and hello to
crowley.Query(file, "users[*].age").agg("sum")
Say goodbye to
with open(f, "rb") as file: for i, name in enumerate(ijson.items(file, "users.item.name")): if i == 2: result = name break
and hello to
result = crowley.Query(file, "users[2].name").values()
Say goodbye to
def worker(args): import ijson with open(args[0], "rb") as f: return sum(1 for _ in ijson.items(f, args[1], multiple_values=True)) with ProcessPoolExecutor() as pool: counts = list(pool.map(worker, [(f, "repo.name") for f in glob("logs/*.jsonl")]))
and hello to
counts = Query("logs/*.jsonl", "[*].repo.name").count()
Say hello to all the things you couldn't do at all with simple prefix matching, like
Ranges
users[1:3].name: return the second, and third elements in the users array
Disjunctions
users.(name | age): match and return the values of name, age, or both under users
Kleene Stars
a*.b: follow the key a any number of times, then b. Matches b, a.b, a.a.b
Wildcards
*.age: match age under any single field name
Optionals
config.debug?: matches config, and also matches debug if it's there
Special characters
"my.field": double quotes match a literal key containing reserved characters like ., *, [, etc.
Recursive descent
(* | [*])*.name: descend through any combination of fields and array elements, then match name at any depth
It's still in early stages, but already quite usable, and I think with some more testing and polish, it could be production-ready and able to benefit developers pretty soon.
Right now, the PyPI version only has binaries for manylinux, as I'm migrating from GitHub to CodeBerg and ForgeJo CI is a lot more limited. If anyone reading this knows how to set up multi-platform targets for ForgeJo, I'd appreciate opening an issue on the repository.
You can install the Python binaries using pip install pycrowley (for some reason crowley was rejected by PyPI). It's available as a Rust crate as crowley_rs. The documentation on the Rust crate is a bit sparser than for Python, but I hope to fill it out and polish further in the coming weeks.
Also, if you're coming to the Apr 7th RustNYC meetup, I'll be giving a lightning talk on crowley there!